Which words frequent the pages of Pride & Prejudice ?
- Lekha Mirjankar

- Dec 14, 2023
- 3 min read
"It is a truth universally acknowledged, that a bookworm in possession of a data analyst's quill, must be in want of literary adventures."
Good day, dearest readers!
With quills at the ready, let us embark on a venture reminiscent of the grand balls and social intricacies of Jane Austen's novels to find the words that make a frequent appearance in the halls of Pemberley.
Our companion on this literary journey? None other than the timeless Pride and Prejudice.
Step 1: An Invitation to NLPfield Ball
First things first, let's import the required Python modules.
# Importing requests, BeautifulSoup, nltk, and Counter
import requests
from bs4 import BeautifulSoup
import nltk
nltk.download('stopwords')
nltk.download('vader_lexicon')
from collections import Counter
import matplotlib.pyplot as plt
from wordcloud import WordCloud
We're using requests to get the digital manuscript of Pride and Prejudice from Project Gutenberg. We are making a get request to the website (URL) to fetch the data we need.
# Request Book
r = requests.get('https://www.gutenberg.org/cache/epub/42671/pg42671-images.html')
# Setting the correct text encoding of the HTML page
r.encoding = 'utf-8'
# Extracting the HTML from the request object
html = r.text
# Printing the first 2000 characters in html
print(html[0:2000])
Here, r.encoding ensures that we interpret the HTML correctly, and we store the HTML content in html for further exploration.
Step 2: What Excellent (boiled?) Soup!
Enter BeautifulSoup! We're using it to parse the HTML content and extract the raw text of Pride and Prejudice; this is what we call Data Wrangling.
# Get the text from the HTML
soup = BeautifulSoup(html, "html.parser")
text = soup.get_text()
print(text[1540:8000])BeautifulSoup(html, "html.parser") creates a BeautifulSoup object, and soup.get_text() retrieves the text from it. It's like getting the plain text from a web page.
Step 3: Remove the simpletons
Let’s break down our text into individual words and remove anything that isn't a word (eg. punctuations), a process known as tokenization. The nltk library helps us with that.
# Extract the words
tokenizer = nltk.tokenize.RegexpTokenizer('\\w+')
tokens = tokenizer.tokenize(text)
# Make the words lowercase
words = [token.lower() for token in tokens]Step 4: A Stop for Tea
Stop words are the dull party guests of our text. This includes words like 'a', 'the' that do not add anything meaningful.
nltk provides a stopwords list that we can use to remove them and keep only the words that are of interest to us.
# Load in stop words
sw = nltk.corpus.stopwords.words('english')
# Remove stop words
words_ns = [word for word in words if word not in sw]Here, we load English stop words with nltk.corpus.stopwords.words('english') and then create a new list words_ns excluding these stop words.
Step 5: Count the distinguished words
Finally, we present the most distinguished words!
The Counter class from the collections module helps us count the occurrences of each unique word.
# Initialize a Counter object from our processed list of words
count = Counter(words_ns)
# Store 10 most common words and their counts as top_ten
top_ten = count.most_common(10)
# Print the top ten words and their counts
print(top_ten)We use Counter(words_ns) to create a frequency distribution, count.most_common(10) gives us the top 10 words and their counts, and finally, we print them.
Output:

As expected Elizabeth and Darcy make an appearance right at the top.
The topmost word is Mr which to me was surprising, I had expected it to be one of the prominent characters (mostly Elizabeth), we can owe this to the fact that Elizabeth is often called as 'Lizzie' by her dear one's. Some more analysis can be done to confirm this.
And ofcourse we have Bennet in the list.

Step 6: Presenting the most noted words
Now, let's visualize! We're creating a word cloud using the wordcloud library and matplotlib.
# Visualize word frequency with a Pride and Prejudice-themed word cloud
wordcloud = WordCloud(width=800, height=400, background_color='#e0d6ff', colormap="RdPu").generate_from_frequencies(dict(top_ten))
# Display the word cloud with a soft Regency color palette
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Word Cloud of Pride and Prejudice', fontsize=16, color='darkslategray')
plt.show()Output:
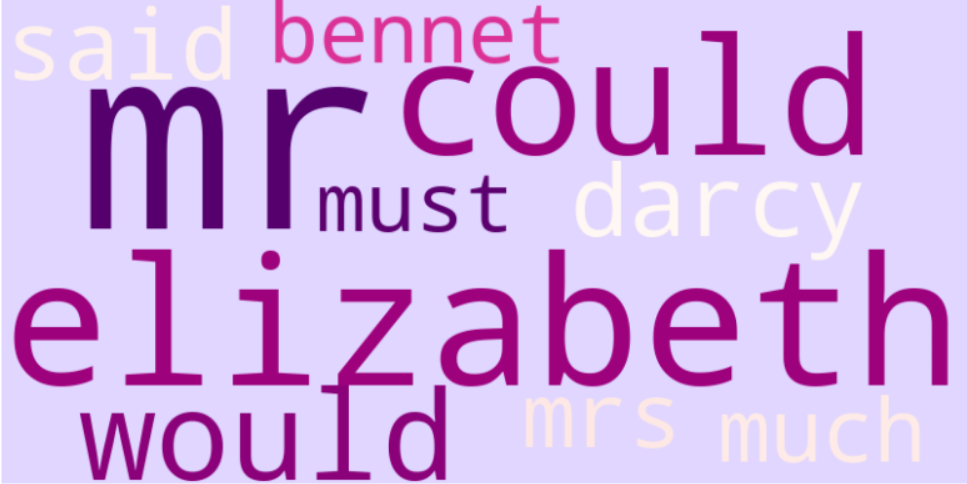
And there you have it- the top 10 debutantes of Pride and Prejudice.
This is day1 of my #100daysofdata challenge.
Needless to say I had the most fun analysing the most frequent words in my most favorite novel :P
Let me know if you have any suggestions or ideas for me.
Happy analyzing!

Comments